参考资料
DeepLearning Bengio Chapter 10
Sequence Modeling: Recurrent and Recursive Nets
从multi-layer networks到recurrent network需要用到早期在机器学习中发现的想法:共享参数。共享参数使得网络可以运用到多种形式的数据上,并且在它们之间产生泛化。
卷积网络也是一个共享参数的网络,只是它的共享方式是通过共享input中相邻的输入,而RNN则是与之前的输入共享参数。
Unfolding Computational Graphs
下面的公式是简化版的RNN公式,这也是一次unfold操作。
$s^{(t)}=f(s^{(t-1)};\theta)$
当系统收到外部信号$x^{(t)}$ 驱动时,式子就变成了
$s^{(t)}=f(s^{(t-1)},x^{(t)};\theta)$
许多的RNN用类似的公式来描述自己的隐含层单元
$h^{(t)}=f(h^{(t-1)},x^{(t)};\theta)$
而输出层就是靠着读取隐含层来作出预测的。
Recurrent Neural Networks
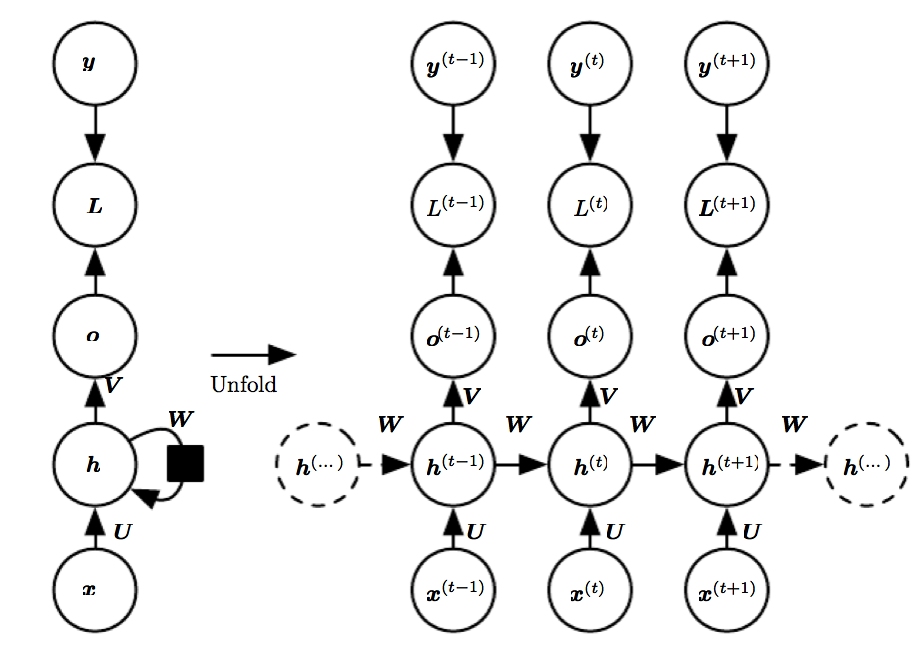
前向过程是
$a^{(t)}=b+Wh^{(t-1)}+Ux^{(t)}$
那些有从输出层到隐含层的模型是可以使用teacher forcing,也就是在训练过程中不是把前一时间的网络输出输入到后一时刻的网络输入中,而是将ground truth y输入到后一层中。
训练RNN的一个方法是BPTT,其实就是Back Propagation Through Time。只要把这些网络按照时间展开,就可以看作是一个前馈网络。
Bidirectional RNNs
双向RNN网络可以使用未来的信息来帮助确定当前的状态。双向RNN网络实际上是结合了两个网络,一个是从序列头开始的,另一个是从序列尾部开始的。
Encoder-Decoder Sequence-to-Sequence Architectures
这个网络是用于将一个序列转换成另一个序列。
通常RNN将输入称作context。
2014年才提出了可用于可变长的序列转换的RNN网络。
一个RNN叫做encoder,它产生context,另一个RNN叫做decoder,它消费context。其中的context是固定长度的。
2015年的时候,有人提出了可变context长度的RNN网络。
Deep Recurrent Networks
有三种变得deeper的方式。
Recursive Neural Networks
RNN一般都值的是recurrent neural network。
Challenge of long-term dependencies
学习这样的网络的时候,传回去的梯度要没会消失要么会变得过大。