YARN
简介
YARN在hadoop 2中被引入,用于改善MapReduce,但是它也被用于支持别的计算框架。YARN提供API用于请求和使用集群资源,但这些不是直接被用户的代码使用的。
如何工作的
YARN通过两种守护进程来提供它的核心服务,一个是resource manager,另一个是node managers。后者会启动和监控containers。一个container会执行一个特定程序的进程,同时包括一系列的受限制的计算资源。一个container可以是一个unix的进程,或者是linux的cgroup。
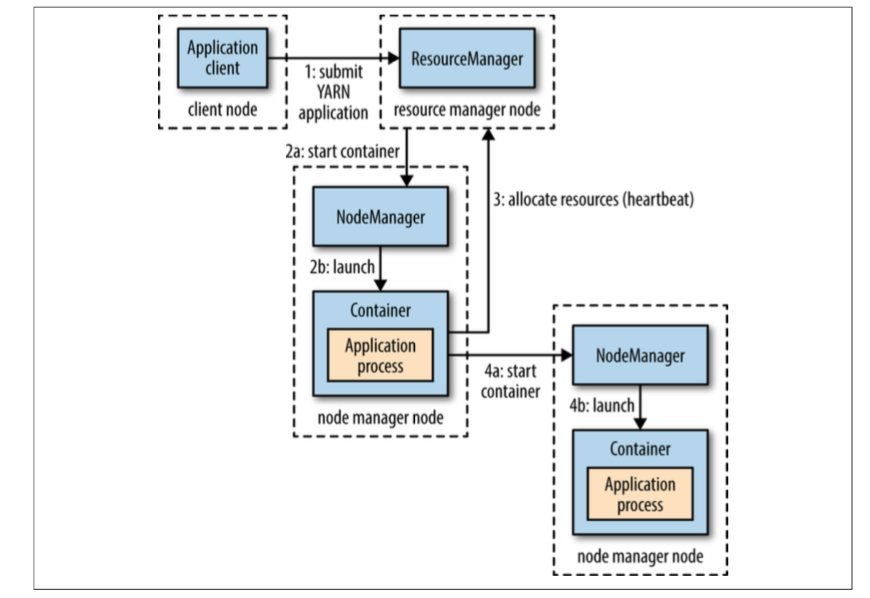
本地化是可以让集群的带宽的利用率达到最大。通常情况下,会在存有数据的node上启动,再不行就在同一个rack上启动,再不行就随机任意一个node。
Spark是事先就申请好固定的资源用于计算,而MapReduce则是动态地,先为map申请资源,然后再为reduce申请资源。
应用生命周期
- 一种模型是每个用户job一个应用,MapReduce采用的就是这样
- 第二个是每个流程或用户对话一个应用,这个更高效,因为container可以复用,Spark采用的是这种。
- 第三种模型是长期运行的、被用户共享的应用。这种应用的好处在于反应快。
建立YARN应用
Slider可以用来直接启动已有的应用在YARN上。
Apache Twill也是类似于Slider。
MapReduce 1中有jobtracker和多个tasktracker来控制job的执行,其中jobtracker负责任务的调度以及任务的监控(失效重启等)。
MapReduce 1中的jobtracker对应着yarn中的 Resource Manager、application master和timeline server,而tasktracker对应着node manager,slot对应着Container
YARN最大的好处在于它不再只为MapReduce使用,它可以为很多别的计算框架提供服务。
YARN调度
提供了三种scheduler
- FIFO
- Capacity
- Fair Scheduler
但是FIFO会导致小任务被大任务阻挡,Capacity Scheduler有专用队列,每个队列有它的容量,这个容量表示它所能给队列中的任务分配的最大计算资源。但是在有空余资源的情况下,系统是有可能给队列中等待的资源分配一个大于它的容量的计算资源。它不会通过杀死其他Container来抢占资源,所以当自己的计算资源被弹性队列机制拿走的时候,它也只能等着别的队列用完之后换给它。为了避免这个情况,是可以配置一个最大容量,如果没配置则有可能会用光这一级的所有资源。
Fair Scheduler则是让每次新来的任务都从前一个任务中分出一半的资源。
延迟调度
为的是能够增大在本地运行的机会